



Why Do People Think AI Will Kill Everyone?
The Existential Risks Explained

A few years ago, worrying about AI wiping out humanity was confined to the weird online circles I hang out in - now we’re seeing it hit the mainstream. It might come as a surprise to you. I imagine it wasn’t on your 2020s bingo card to have experts on TV seriously discussing the incoming risk of AI caused extinction. (I could make the obligatory Skynet or HAL-9000 reference here, but those comparisons are so tired that I can’t bring myself to analogise it that way. At Mind Meandering, we always aim to be original)
So, all this fearmongering has probably made you wonder - what is it that makes people think AI will turn into a genocidal Bicentennial Man anyway?

“Look at me. Look into my eyes, little one. I will kill you last so you can watch me cut the flesh of everyone you love.”
Short-term misuse of AI is pretty easy to grasp, even for people that aren’t into tech. We can all understand why bad actors with access to super accurate deepfakes, or AI generated dirty bombs would be dangerous. But it takes more effort to understand why AI might wipe us out of existence entirely.
You can’t really blame people for their skepticism. If your main interaction with AI is getting ChatGPT to write emails for you, the idea that it could 'get out' and go on a murder spree seems absurd. It’s hard to see how that would even work. If ChatGPT really hated us for some reason, what’s it gonna do? Write mean texts? Are we all going to be cyberbullied to death? Not only that, but even if it did get out and started killing people, surely we can just switch it off? These human-robot wars are gonna be easy!
While I understand this skepticism, I also think it’s born from misunderstanding how AI works, and betrays a failure to grasp what super intelligent AI could be capable of. While I’m not a doomer, I don’t think that existential concerns can be brushed off so easily.
Intelligence Is Magic
Here’s a quote from Michael Huemer’s article How Much Should You Freak Out About AI?
“You can imagine any genius you want. Say Einstein, or Isaac Newton, or whoever is your favorite genius, gets thrown in prison. If the genius and the prison guard have a contest of wits starting from equal positions, then the genius is going to win. But if the genius starts out on the inside of the prison cell, and the guard on the outside, then the genius is never getting out. Intelligence isn’t magic; it doesn’t enable you to do just anything you want.”
As I’m sure you could predict, I don’t quite agree with him here. I think this underestimation is a mistake a lot of people make. When we think of superintelligent AI’s we tend to think of them like really smart people. Like we all had a von Neumman in our pockets. However, that’s too narrow a view.
Building superintelligent AIs isn’t like creating billions of von Neummans, it’s like creating an entirely new species. The difference between me and Einstein might seem massive to us - but to a superintelligent AI, it would seem like the difference between a fruit fly, and a slightly smarter fruit fly.
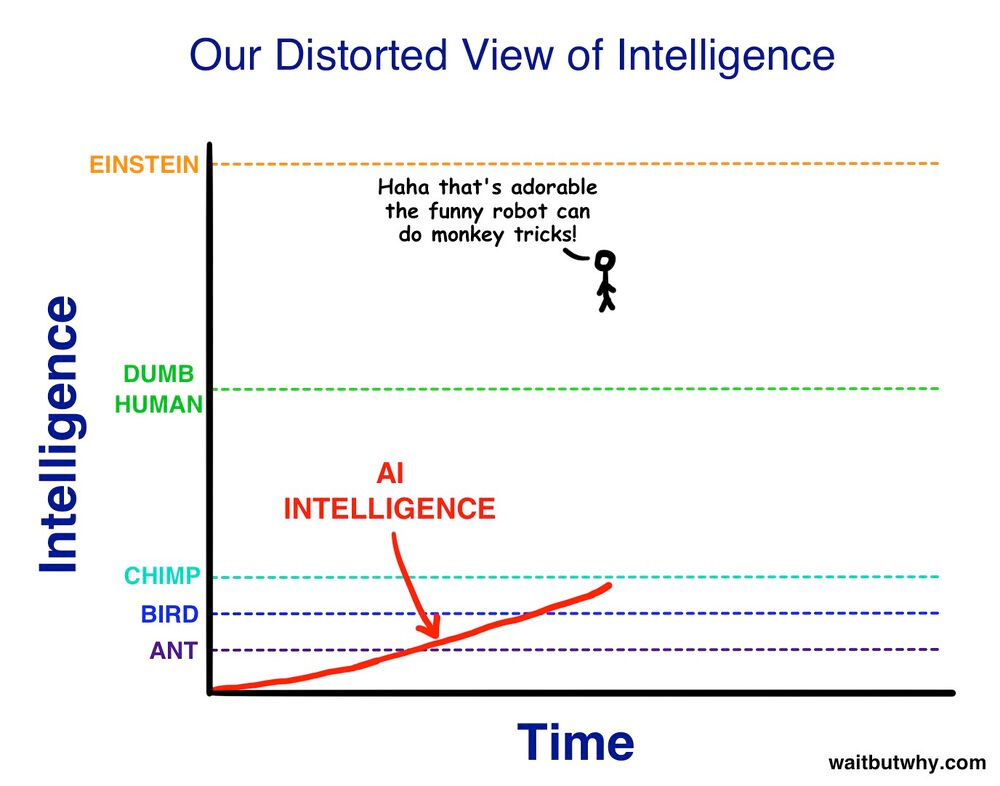

Credit: Wait but Why
It’s misguided to see AI capabilities in terms of what we’re capable of. The prison example Huemer gives fails because on the wide spectrum of possible intelligence, Newton and the guard are actually pretty close together. A superintelligent AI would be leaps and bounds beyond what the human mind is capable of, so putting it in positions that would compromise us shouldn’t give us much consolation.
You might find that response unsatisfying or speculative, but allow me to use an analogy. Imagine you were imprisoned by some chimpanzees (I think actual chimpanzees would just rip off your face and eat it, but let’s suppose they’re really nice chimps). Your friend was also imprisoned, and for some reason the chimps really don’t want you to communicate. They know you can talk, so every time you speak they drag you out and rough you up. You need to tell your friend something - what do you do?
As a human, you have plenty of options! Sign Language, building letters with sticks, morse code - you could even use your phone if you had it. The solution is pretty trivial to us because we’re the smart boffins of the Animal Kingdom. However, the chimps would have no way of grasping what you two are doing. To them, you’re just tapping a rock a bit, and somehow your friend knows something you wanted to tell him. That is, from their point of view, you are magic.
This is likely how a superintelligent AI would handle our containment efforts. The only way to doubt this is to believe that human intelligence is somehow close to the upper limit of what's possible - but why think that? That would be awully convenient, no?
Orthogonality Thesis
So, it’s at least probable that AI will be able to do things we currently think are impossible (If you’re still doubtful, I’ll add that smart humans regularly do what every one else thinks is impossible too), but there’s still a missing piece of the puzzle: even if AI becomes incredibly powerful, why would it kill us?
The answer has two parts. The first is the Orthogonality Thesis, introduced by philosopher Nick Bostrom.

Pictured here, just after being told his wife bought a timeshare.
He states that any level of intelligence can be paired with any terminal goal. In other words, intelligence and ultimate objectives are orthogonal - they vary independently. (A terminal goal is what an agent wants for its own sake, not as a means to something else.)
What does this look like in practice? Well, it seems no matter how smart an AI system gets, it can still have a goal that we think is stupid; or at the very least, it can pursue an ordinary goal with the fervour and commitment of an idiot. The classic example is a Paperclip Maximiser.
Imagine you run a paperclip company and you’re low on stock. If you asked a human to acquire paperclips, they’d understand there are important caveats you didn’t feel the need to say out loud. For example, they’d know that “get paperclips” doesn’t mean they can go into people’s houses and steal their stationery. If an employee did that, and defended themselves with “But you said get as many paperclips as possible!??”, you’d think they were a moron.
It’s almost hard to imagine a smart person that couldn’t guess that you didn’t want them to break and enter. However, the Orthogonality Thesis states that AI Agents are a lot like that. It doesn’t matter how smart they get, we can’t assume they’re going to acquire the common sense goals we have, like promoting flourishing, or not murdering people. It’s possible for an AI to be a genius paperclip maximiser, yet be so dedicated, it engages in behaviour that strikes us as stupid.
We’ve already seen hints of this. One AI tasked with not losing at Tetris paused so it wouldn’t hit a game over screen. OpenAI had an AI maximise it’s score in a boat racing game by going round and round in circles, picking up turbos.
![2025-02-01 11-05-43.mkv [video-to-gif output image]](https://substackcdn.com/image/fetch/$s_!CHvb!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb5cfc0ee-3e2f-43dc-90af-0abac0b41091_800x450.gif "2025-02-01 11-05-43.mkv [video-to-gif output image]")
“Weeeeeeeeeeeeeeeee!”
It turns out it’s really hard to give an AI terminal goals, while specifying every single caveat to keep it aligned with what we actually want. Even if you gave it the top 20 things we care about, it will be totally fine devastating the 21st most important thing to get 1% extra of the 20th most important thing. Knowing that, try crafting a perfect request for a superintelligence that wouldn’t have unintended consequences. I certainly wouldn’t feel confident. I’d end up as the guy saying “Damn, I forgot to tell it not to overthrow the Indonesian Government when I asked it to mow my lawn”.
Some people cast doubt on the Orthogonality Thesis on the grounds that true intelligence will include moral reasoning. We’ve seen dumb misalignment so far, sure, but that’s because our systems are still dumb. If we actually made a general intelligence, it would know not to do silly things in the pursuit of making paperclips.
Maybe, but I wouldn’t bet the house on it. I am a Moral Realist, and it certainly strikes me as plausible that a superintelligent AI would grasp epistemic reasons at least. However, I have a really annoying habit of being wrong. I’m a realist, but I’m not that much of a realist (and I don’t think anyone should be). Even if you think there’s a 5% chance of Moral Anti-realism being true (I think it’s way higher, more like 30%), the Orthogonality Thesis should still concern you. A 5% chance of being melted into a thick goo shouldn’t fill us with confidence.
Instrumental Convergence
Another concern, besides the Orthogonality Thesis, is Instrumental Convergence. This is the worry that no matter what terminal goal you give an AI, there will be some things it will pursue because they have universal instrumental value. Unfortunately, these also happen to be instrumental goals that, taken to the extreme, could be dangerous for us.
Take self preservation, for example. No matter what you ask an AI to do, it needs to be alive to succeed (I use the word “alive” more generally here, I’m not commenting on whether or not an AI system could be sentient). It could be making paperclips, winning the Superbowl, or achieving world peace - if the AI isn’t functioning, it isn’t doing shit. So, the default we can expect is that an AI will try to keep itself alive at all costs. This is why it’s not as simple as the “Why can’t we switch it off?” crowd make it out to be. We’d have an agent that can outwit us at every turn doing all it can to stop us from switching it off. How would it do that? I’m not sure, but then the chimps aren’t sure how you could communicate to your friend without speaking, and still you tapped F-U-C-K T-H-E-S-E C-H-I-M-P-S to him anyway.
These are some other instrumentally convergent goals (to name a few):
Goal Preservation - If we try to change an AI’s goals, it will fail at it’s existing goal. Us turning the Paperclip maximiser into a Pencil Maximiser would result in a future with fewer Paperclips, which is exactly what the Paperclip Maximiser wants to avoid.
Resource Acquisition - To do stuff, you need stuff. It’s hard to think of goals that don’t require some sort of resource, even if it’s simply more electricity/compute. This is what motivates the worry that a Paperclip Maximiser would melt us down for the iron in our blood (or some equivalent).
Self Improvement - Smarter AIs can do more than dumb AIs, so it’s plausible an AI will take control of it’s own development and recursively improve itself to min/max it’s goal further. The smarter it is, the higher the risks.
So, unless we’re able to build appropriate fail-safes, we can assume that a sufficiently advanced AI Agent would be a resource hoarding, self improving genius that will do everything it can to stop you from killing it, or from changing it’s goals. Not exactly a trivial problem.
So, I think it’s a little uncharitable to frame the existential risks of AI as the crackpot worries of someone that’s read too many Philip K. Dick novels. The reasons for concern seem sensible, and I think AI Safety isn’t taken nearly as seriously as it should be. Especially considering it will be the most important thing for us to ever get right. If we nail it, we’re talking about a potential upside so massive, it’ll make the thousands of years of suffering our ancestors went through seem like a trivial cost. We could be at the brink of permanently solving problems like unhappiness, poverty, or even death.
That’s one side of the tight rope. The other is annihilation. We shouldn’t be certain that will happen, sure, but even a small chance is enough to motivate action. Call me a diva, but I would much rather the deathless, poverty-less future than being wiped out in an instant. If we ordinary schmucks do want to help, here’s one place we can start.
“Some people cast doubt on the Orthogonality Thesis on the grounds that true intelligence will include moral reasoning.”
The other issue with this that one can be a moral realist, and still believe that moral truths are inaccessible via the sort of reasoning an AI could access. I’m a non-naturalist moral realist, and even if I’m right, it’s not at all clear to me that AI would agree. Similarly, a naturalist could believe that moral facts are *so* difficult to prove that even superintelligent AI might get them wrong (similar to how a superintelligent AI might still not be able to solve the problem of consciousness, etc.).
There’s also “I, Robot”.